

É uma solução nativa de Engenharia do Caos (Chaos Engineering) do Azure, projetada para aumentar a resiliência de aplicações e infraestruturas. Seu objetivo é identificar vulnerabilidades e pontos de falha por meio da injeção controlada de falhas, simulando cenários reais como latência de rede, indisponibilidade de serviços e falhas de armazenamento.
Dessa forma, permite antecipar comportamentos inesperados em condições adversas, possibilitando a validação de mecanismos de resiliência, recuperação e continuidade antes que esses problemas impactem os usuários finais.
Imagine este cenário
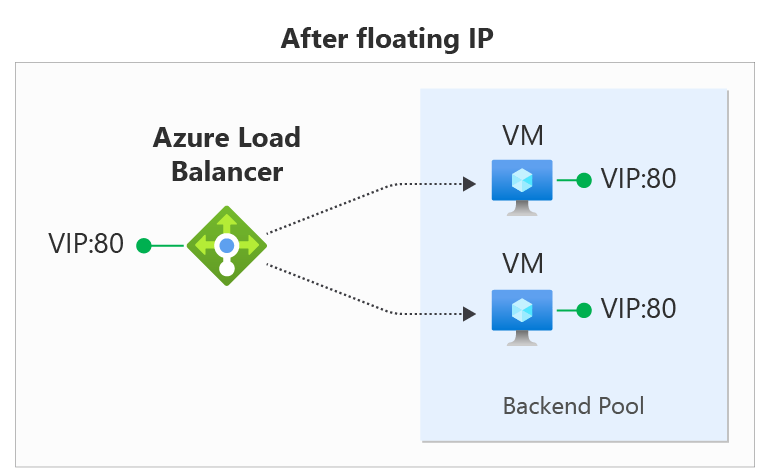
A arquitetura apresentada demonstra um cenário com Azure Load Balancer distribuindo o tráfego de entrada (VIP:80) para múltiplas máquinas virtuais (VMs) em um backend pool, garantindo alta disponibilidade do serviço.
Diante desse contexto, é fundamental conduzir um teste de confiabilidade e resiliência utilizando práticas de Engenharia do Caos, por meio do Azure Chaos Studio. O objetivo é simular falhas controladas — como a indisponibilidade de uma das VMs, seja por crash, desligamento intencional ou entrada em modo de manutenção — e avaliar o comportamento da solução.
Durante o experimento, deve-se validar se o Load Balancer continua distribuindo corretamente o tráfego apenas para as instâncias saudáveis, sem impacto perceptível ao usuário final. Isso inclui verificar:
- Continuidade do serviço (sem indisponibilidade)
- Tempo de resposta e degradação de performance
- Funcionamento dos health probes do Load Balancer
- Capacidade de recuperação automática do ambiente
Essa abordagem permite antecipar falhas reais, identificar pontos de fragilidade e garantir que a solução mantenha sua operação mesmo diante de cenários adversos, reforçando os pilares de alta disponibilidade e resiliência na arquitetura.
Vamos trabalhar isso na prática:
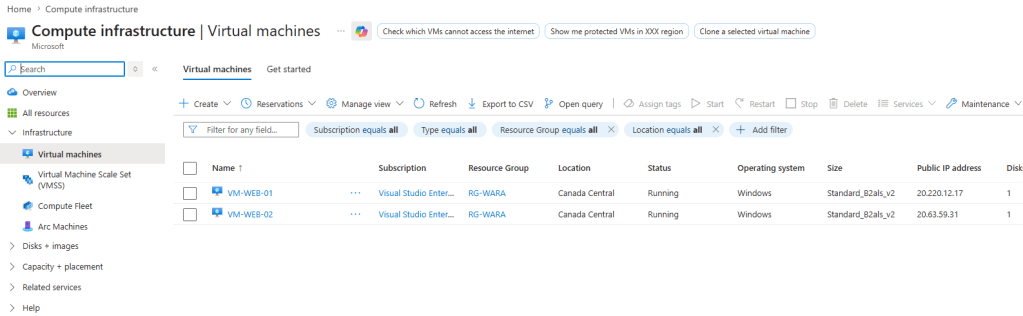
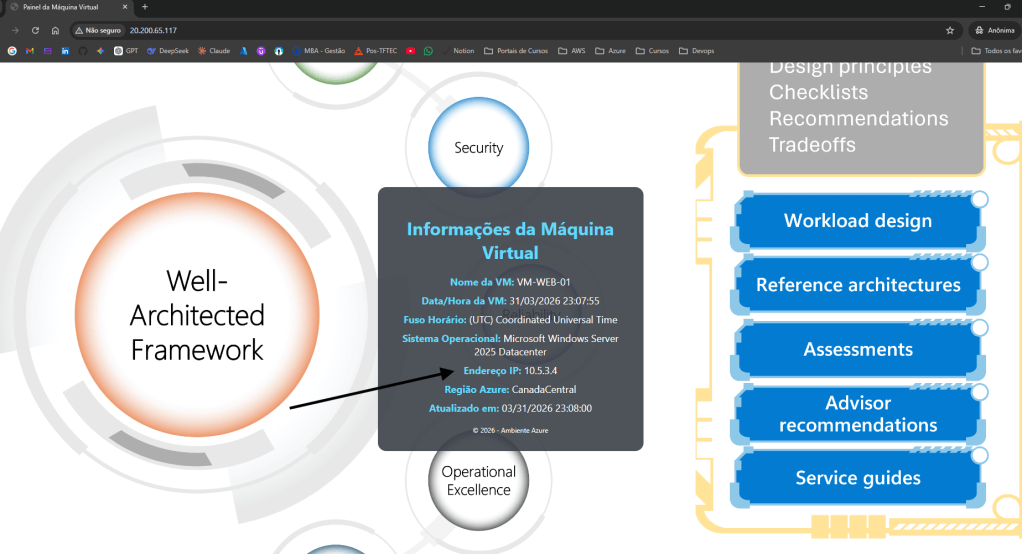
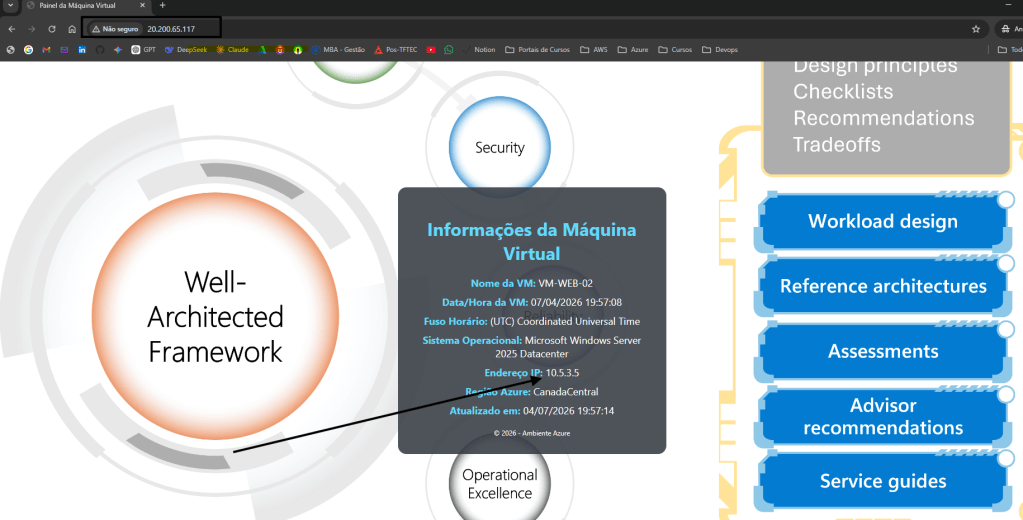
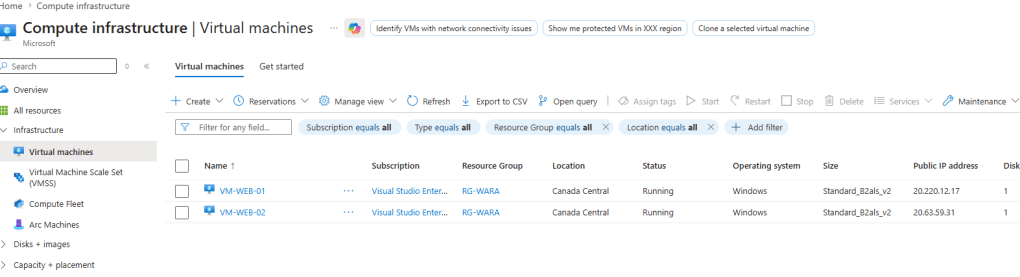
Neste cenário, em minha assinatura, tenho duas VMs que sustetam o serviço web:
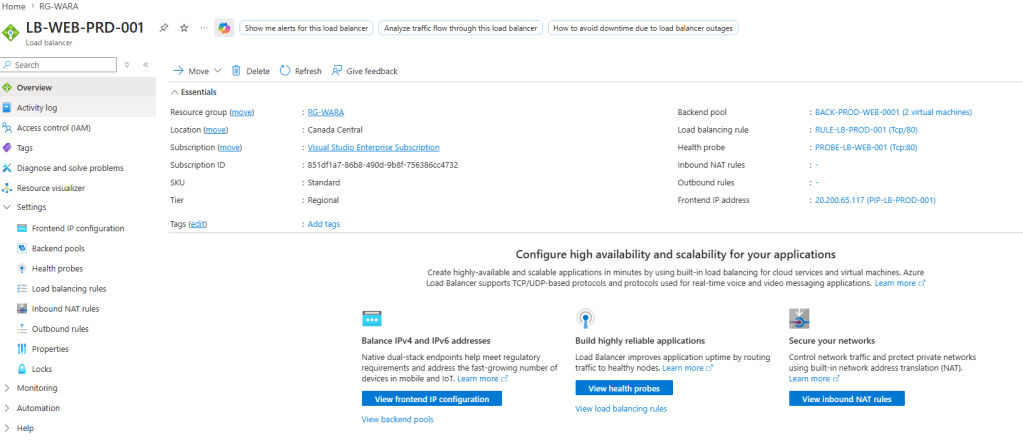
Onde tenho o load balancer configurado conforme a imagem a seguir:
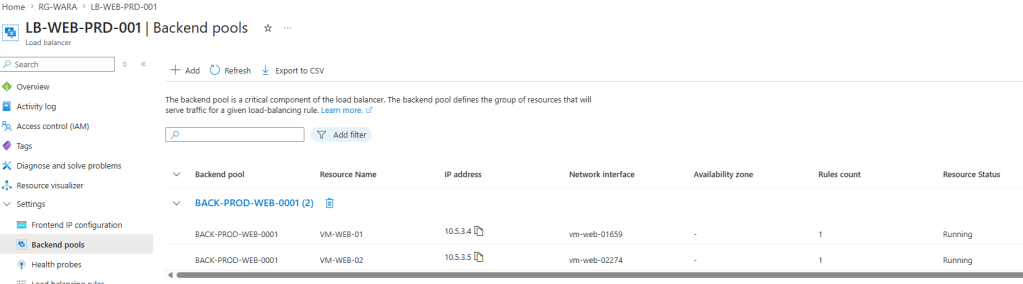
Em seu backend pools tenho as Vms Web01 e Web02
A ideia é validar, por meio do Azure Chaos Studio, a continuidade e resiliência deste serviço web diante de falhas controladas.
O acesso à aplicação é realizado via IP público 10.20.65.117, associado ao Load Balancer. Conforme ilustrado na imagem, o balanceamento de carga distribui as requisições entre as máquinas virtuais com IPs privados 10.5.3.4 e 10.5.3.5.
O objetivo do teste é verificar se o serviço permanece disponível mesmo em cenários de indisponibilidade de uma das VMs, simulando eventos como falhas, desligamentos ou manutenção planejada.
Vamos a guia de configuração do Chaos Studio, acesse o Portal do Azure e Busque:
Esta será sua tela principal de boas vindas
Vamos escolher um alvo para o nosso teste que será a VM Web 01, clique em Targets
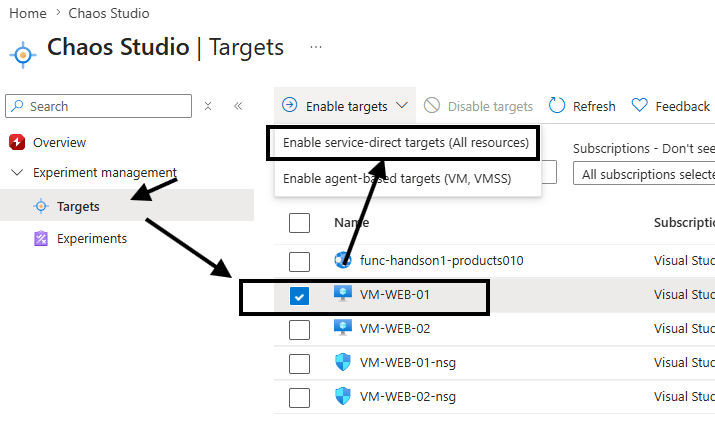
Selecionamos a VM – Web 01, clicamos em Enable Targets e Em seguida na opção Enable service-direct targets (all resources)
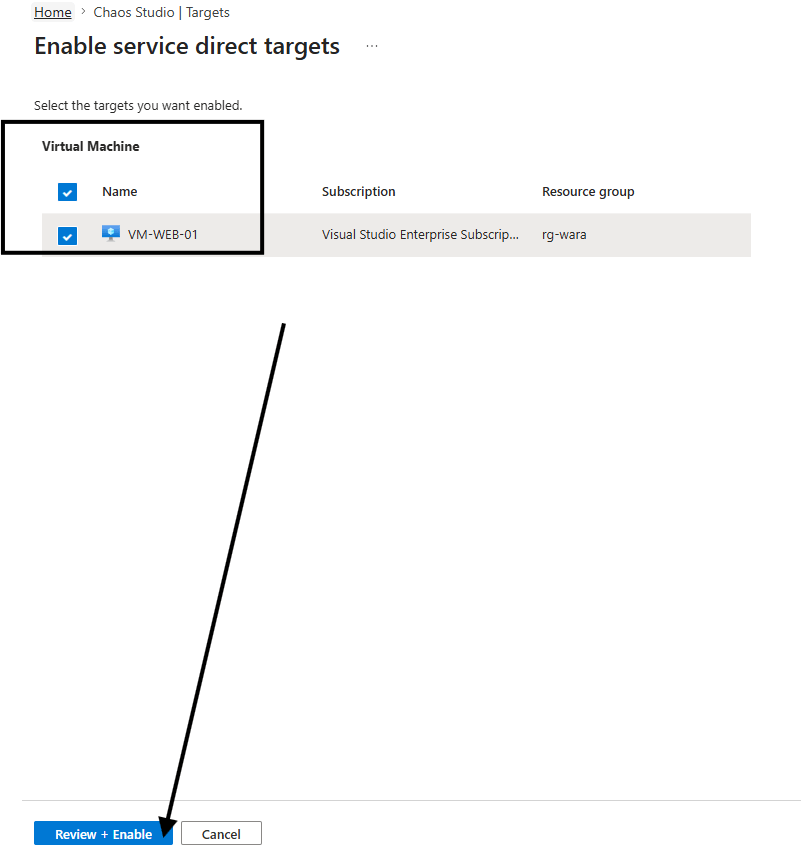
e vamos Ativar o serviço para esta vm web 01 em específico
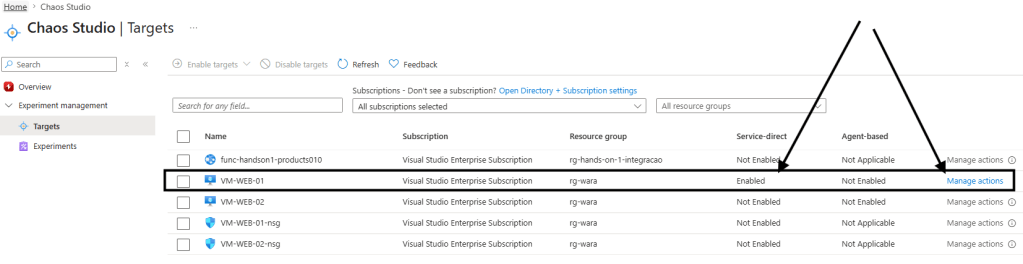
Observe que, após a ativação do serviço, houve alteração nos status apresentados.
Vamos agora iniciar um novo experimento para realizar os testes de falha
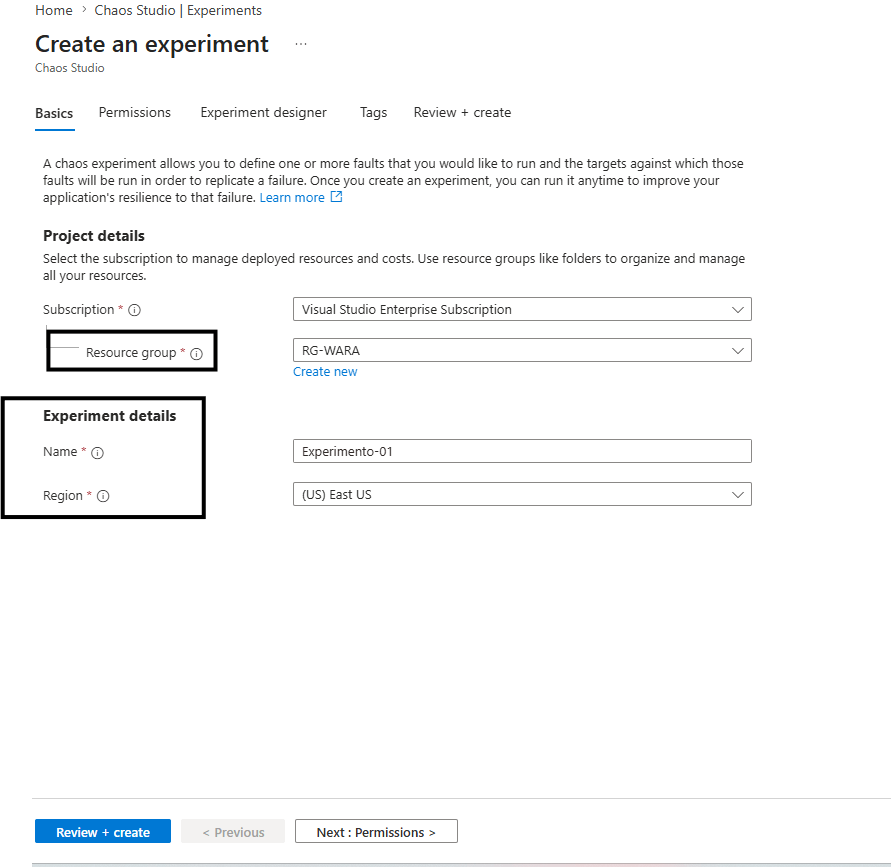
Segue a configuração basic para:
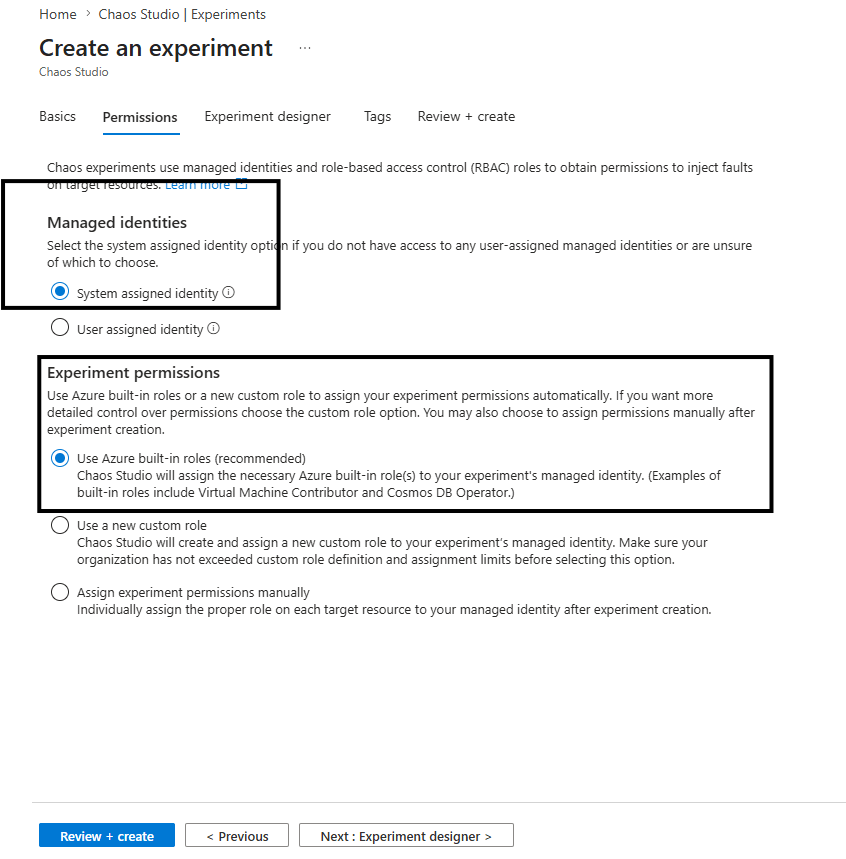
Seguindo com as permissões padrões para criar um usuário de sistemas associado como identidade e suas permissões
Vamos adicionar uma ação :
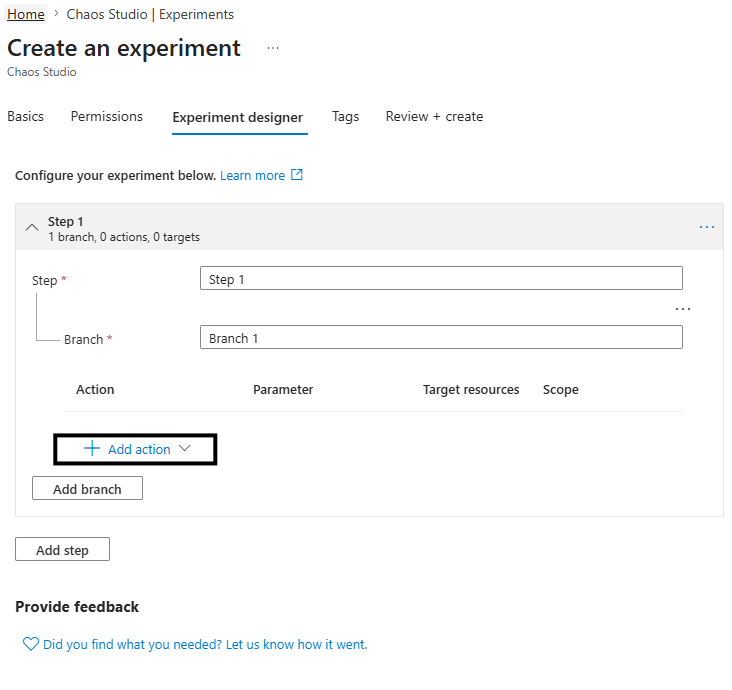
Vamos adicionar uma ação de falha:
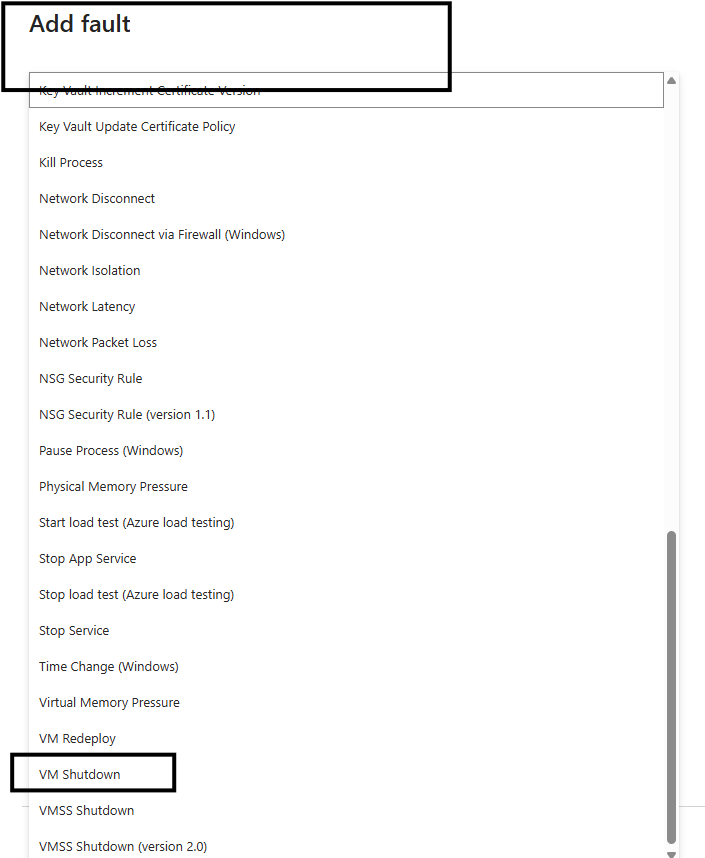
E a falha secionada será VM Shutdown
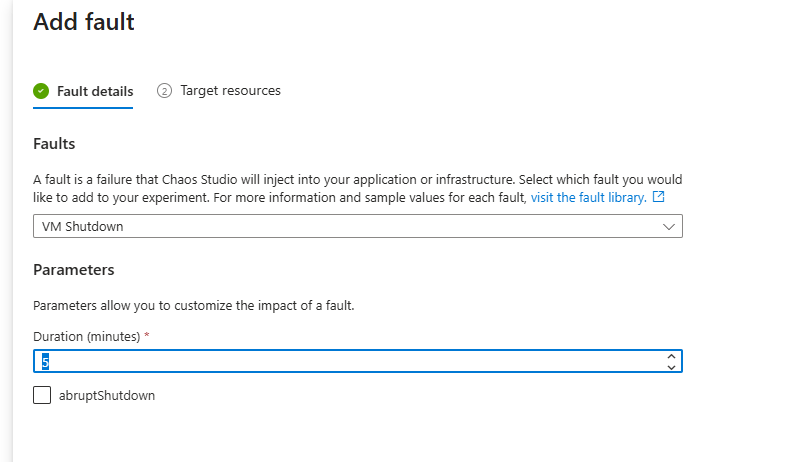
Nesta etapa, é realizada a definição da falha (fault injection) que será aplicada aos recursos-alvo dentro de um experimento no Azure Chaos Studio.
A seção “Fault details” permite selecionar o tipo de falha que será simulada. No exemplo apresentado, foi escolhida a falha “VM Shutdown”, que simula a indisponibilidade de uma máquina virtual, reproduzindo cenários reais como falhas inesperadas, paradas para manutenção ou crashes.
Parâmetros da Falha
A configuração dos parâmetros permite ajustar o comportamento da falha:
- Duration (minutes): Define o tempo, em minutos, em que a máquina virtual permanecerá desligada durante o experimento. No cenário exibido, o valor configurado é de 5 minutos.
- abruptShutdown: Quando habilitado, força um desligamento abrupto da VM, sem o processo de shutdown gracioso do sistema operacional. Esse modo é útil para simular falhas críticas, como perda repentina de energia ou crash do sistema.
Em seguida, definimos o recurso alvo:
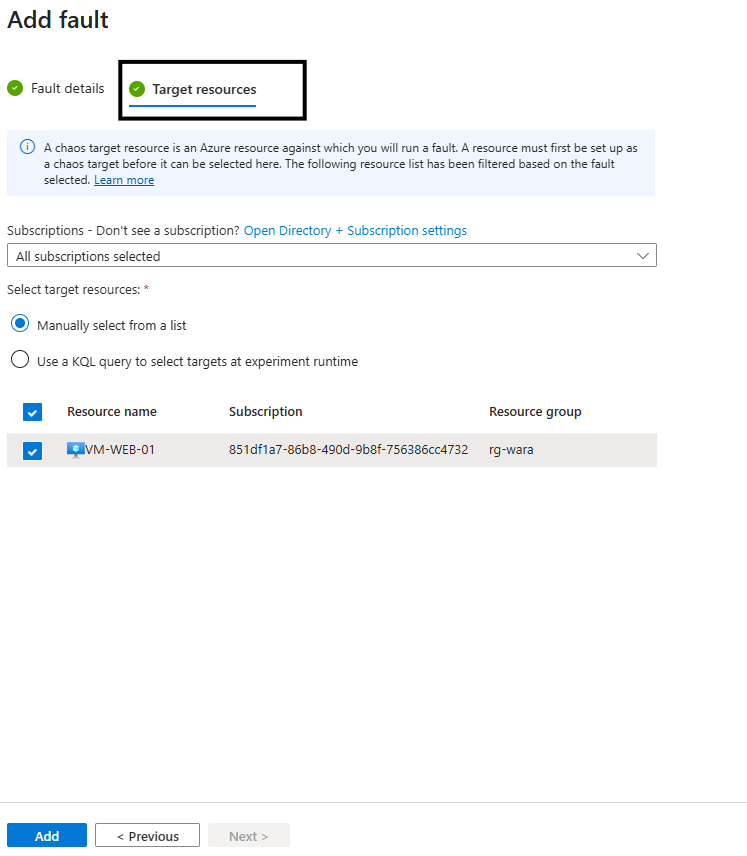
e em seguida, clicar em Review + Create
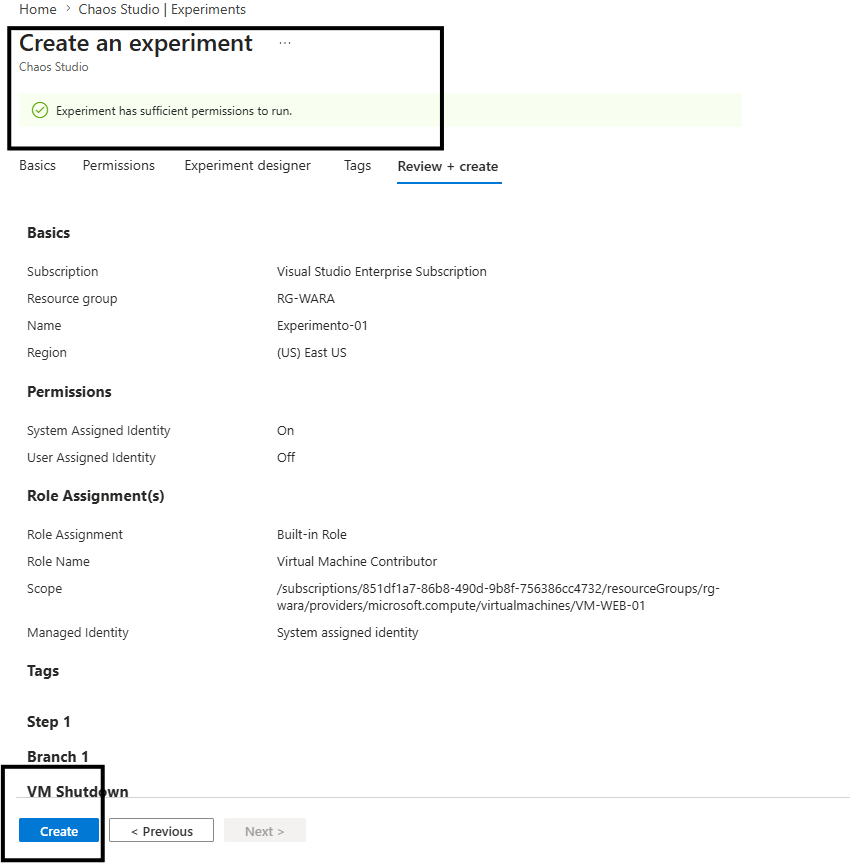
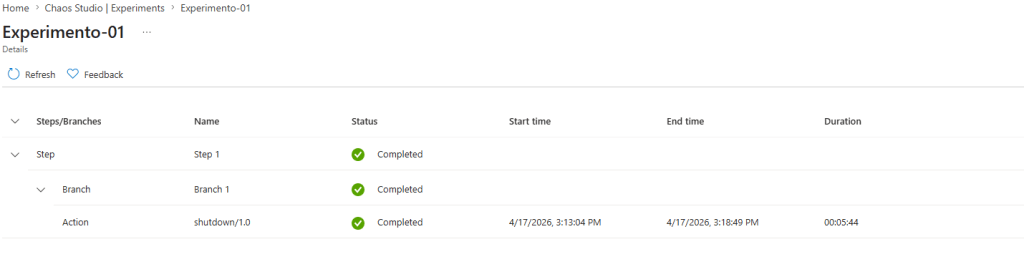
o Experimento foi criado com sucesso:
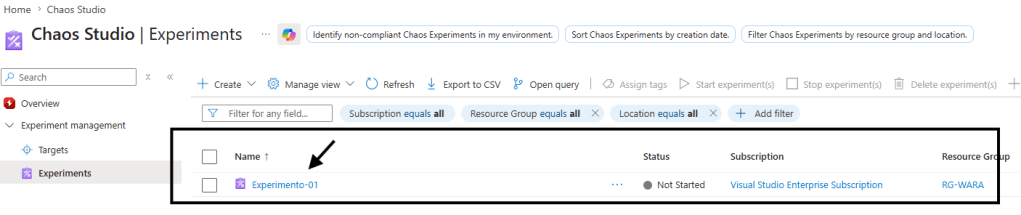
Antes de Iniciar nosso experimento, precisa da permissão em nossa conta de sistemas:
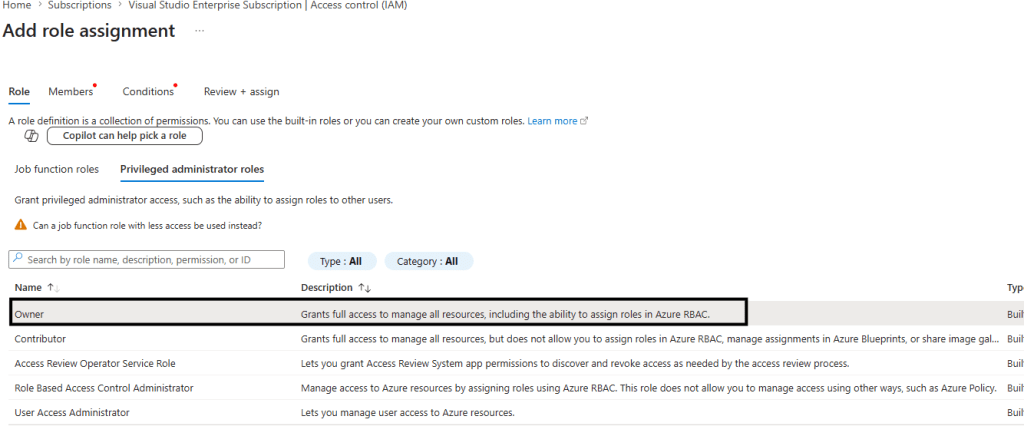
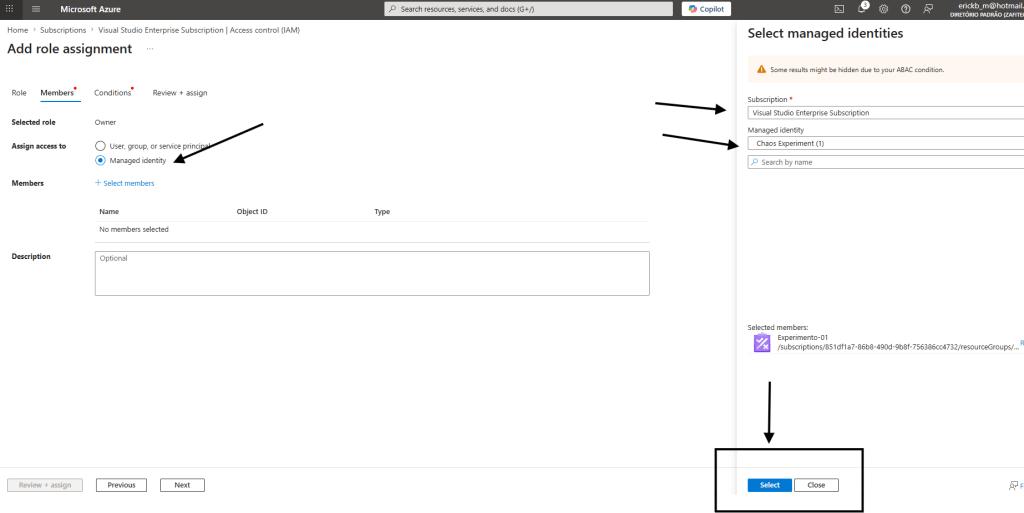
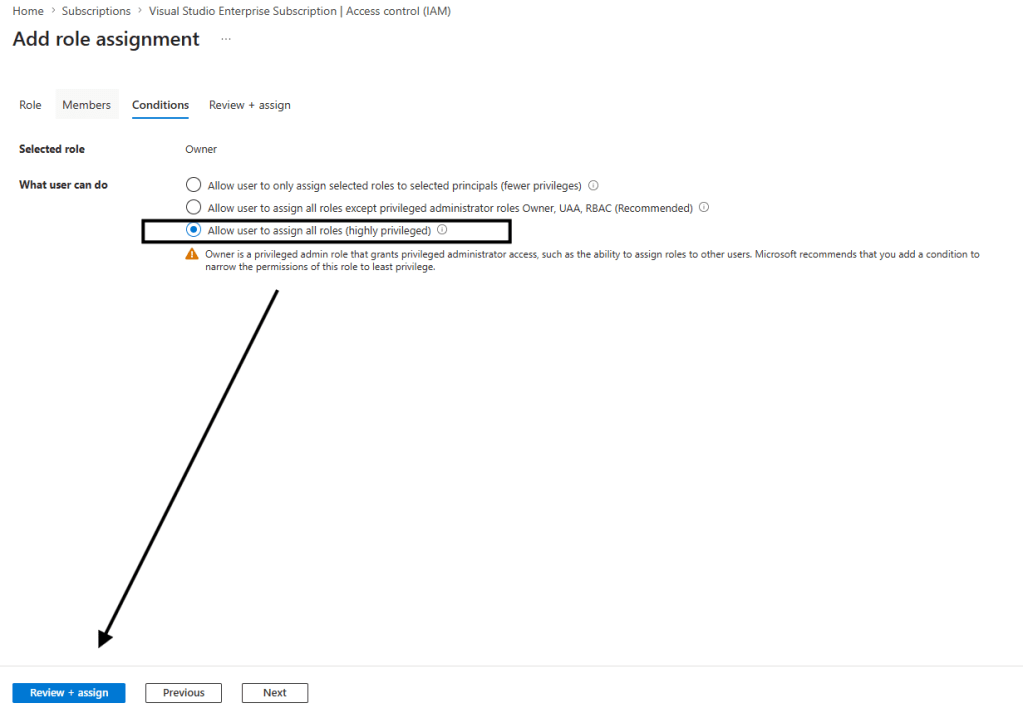
Identidade com a permissão associada .
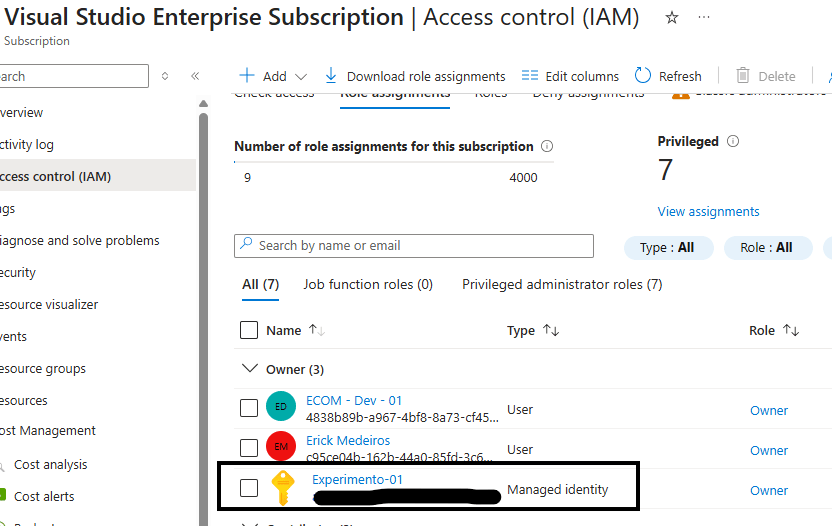
Nesta etapa, o usuário acessa o painel do experimento no Azure Chaos Studio, que atua como o ponto central de controle para execução e monitoramento dos testes de engenharia do caos.
A partir da ação Start, o experimento é iniciado conforme o cenário previamente configurado. No contexto apresentado, será executada uma falha do tipo VM Shutdown na instância Web-01, simulando sua indisponibilidade por um período de 5 minutos.
Durante esse intervalo:
- O Load Balancer redistribui automaticamente o tráfego para a instância saudável Web-02;
- A aplicação deve permanecer disponível, validando a capacidade de alta disponibilidade e tolerância a falhas da arquitetura;
- Os mecanismos de balanceamento e failover são testados em condições reais simuladas.
Após o término do tempo definido:
- O Azure Chaos Studio executa a ação de start da máquina virtual Web-01;
- A infraestrutura retorna ao seu estado original;
- O balanceamento de carga volta a operar com ambas as instâncias disponíveis.
Além disso, o painel exibe informações relevantes como:
- Status do experimento (ex: Not started, Running, Completed);
- Histórico de execuções, incluindo horários de início e término;
- Identificação das execuções, permitindo rastreabilidade e auditoria.
Esse tipo de experimento é essencial para validar, de forma controlada, se a arquitetura suporta falhas reais sem impacto significativo ao usuário final.
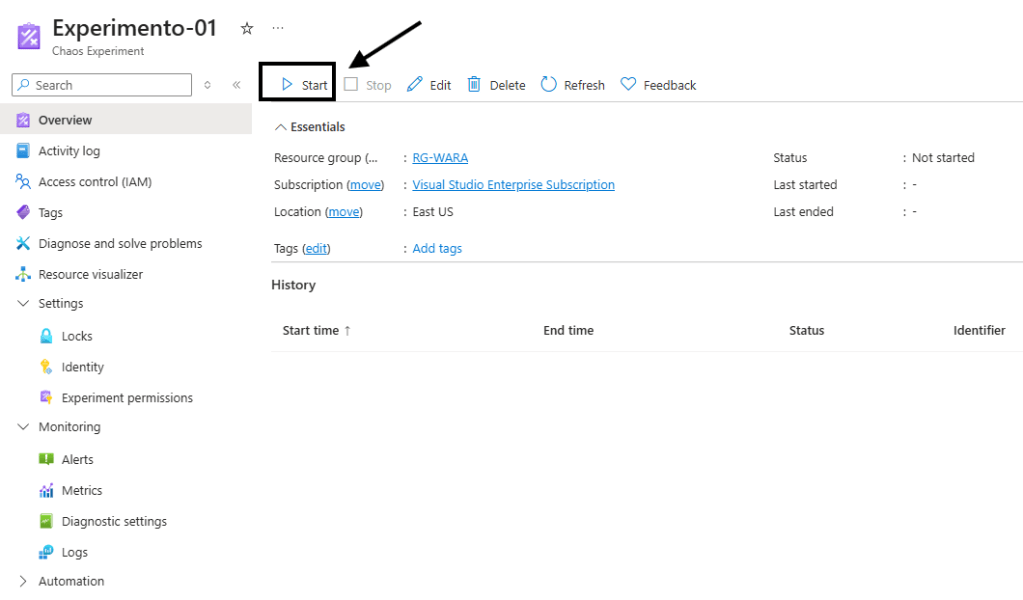
Após iniciar o processo do experimento onde vamos acompanhar em detalhes:
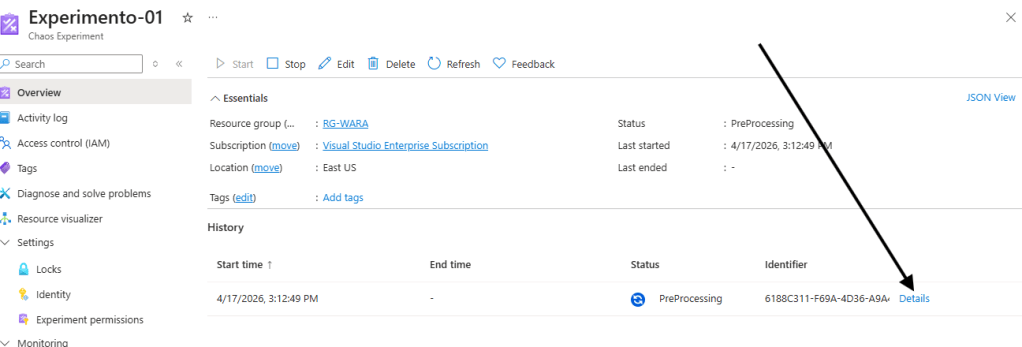
Acompanhando este processo será enviado um comando para desalocar os recursos na máquina virtual.
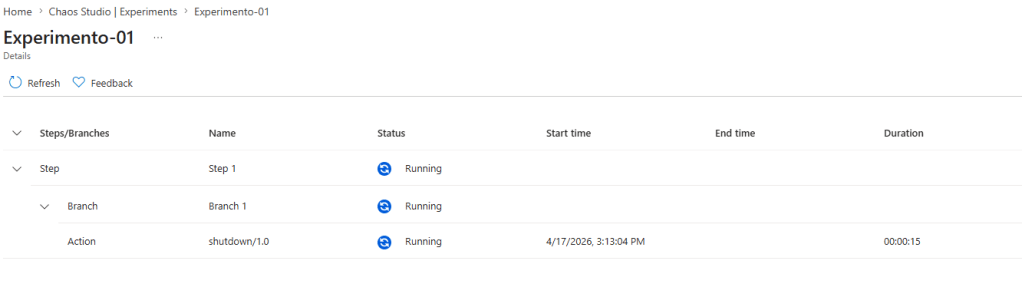
Comando executado com sucesso.
Máquina virtual e site fora do ar diretamente pelo Ip Público alocado para teste externo.
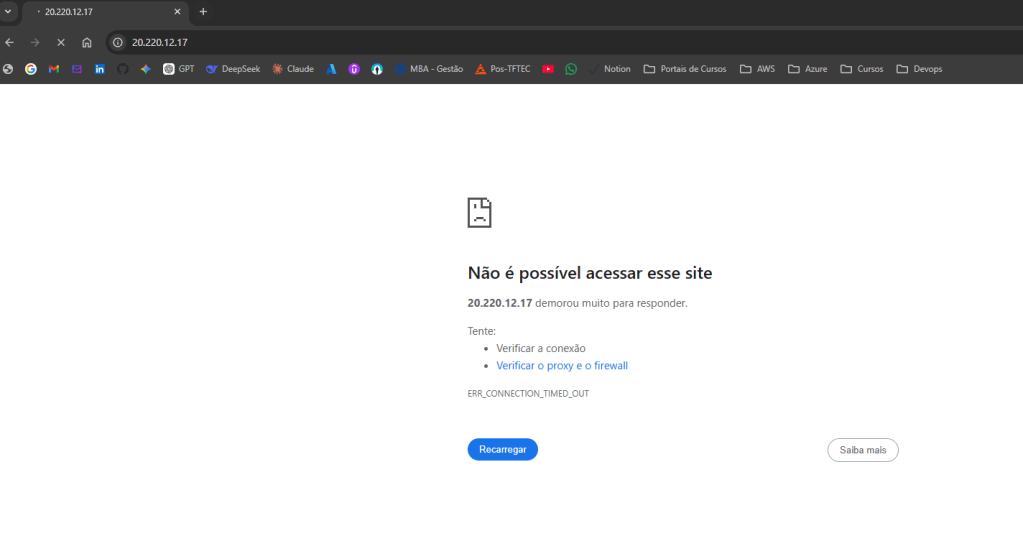
Observe que o Ip Público da vm web 01 tem o final .17

Observe que no Backend Pool do load balanced, a vm web 01 esta em stopped.
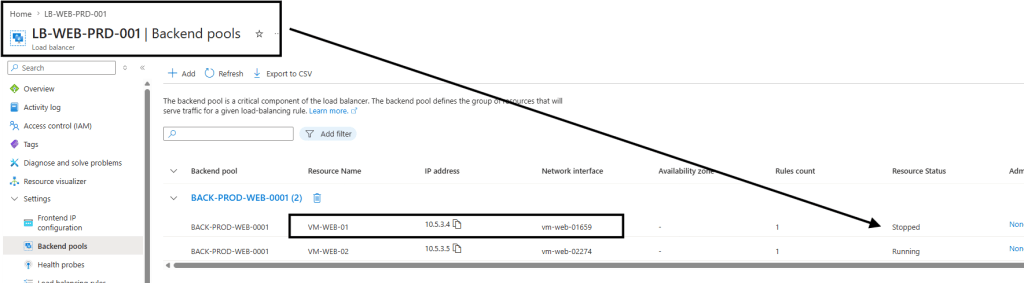
Ip público do Load Balanced já redireciona o trafégo para a Vm Web – 02
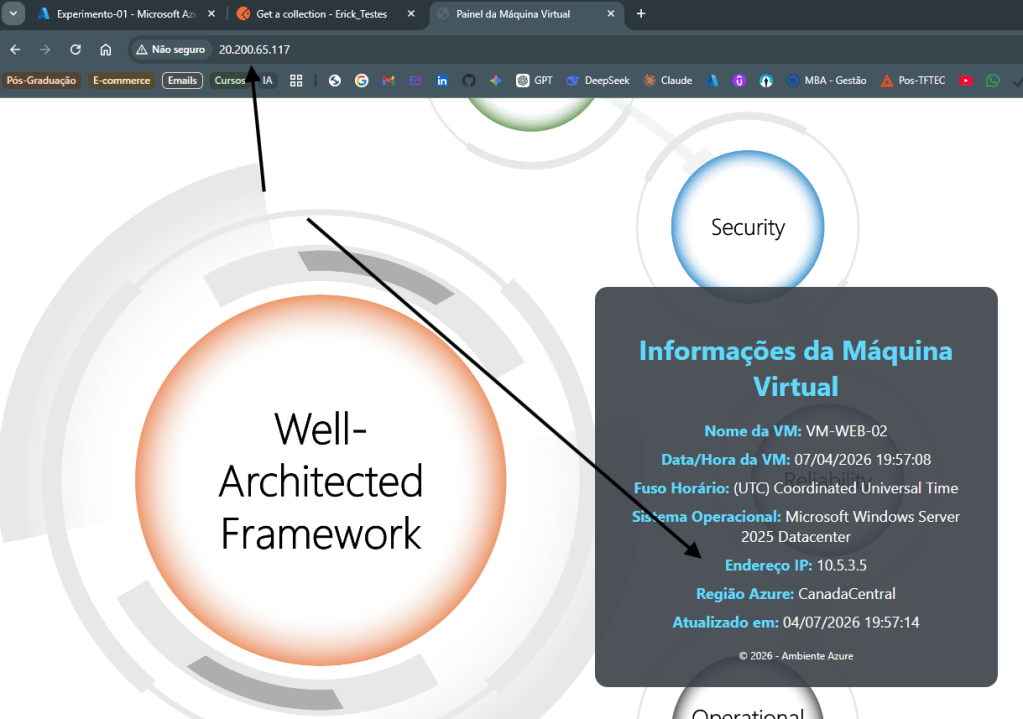
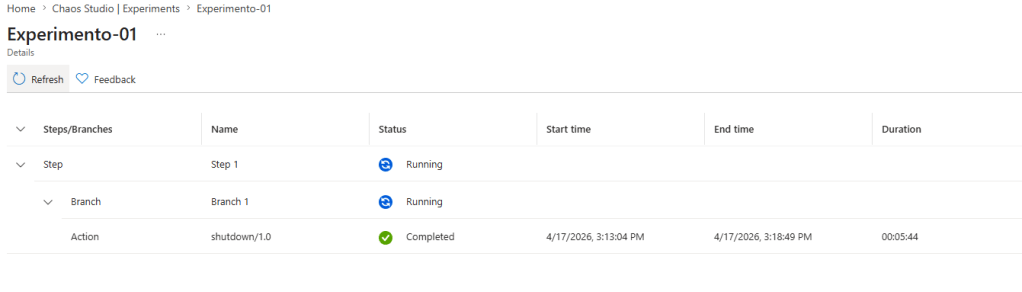
Processo concluído com sucesso.
Após o processo concluído, máquina VM Web-01 está ligada novamente.
Para quem está a começar, o ideal é realizar estes testes primeiro em ambientes de Staging ou Sandbox. Use o Chaos Studio para validar as diretrizes do Azure Well-Architected Framework, especificamente o pilar de Confiabilidade.
Neste laboratório, foi possível implementar e validar, na prática, conceitos fundamentais de Chaos Engineering utilizando o Azure Chaos Studio, com foco em resiliência e alta disponibilidade de aplicações.
Ao longo da execução, foram realizadas as seguintes atividades:
- Configuração do ambiente no Azure Chaos Studio para execução de testes controlados;
- Atribuição de permissões (RBAC) e ajustes de acesso necessários para operação dos recursos;
- Criação e execução de experimentos de caos, simulando falhas reais na infraestrutura;
- Validação do comportamento da aplicação diante de cenários de indisponibilidade, garantindo continuidade do serviço.
Como resultado, foi possível comprovar que a arquitetura é capaz de responder adequadamente a falhas, mantendo a disponibilidade da aplicação por meio de mecanismos como balanceamento de carga e failover automático.
